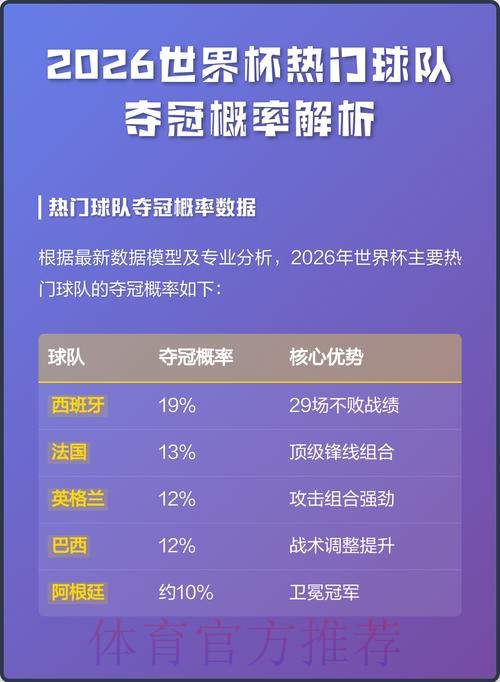
2026世界杯预测模型及应用前景分析
2026世界杯预测模型的核心思路与整体框架
围绕“2026世界杯预测模型及应用前景分析”,最关键的问题是:用什么数据、怎样建模,才能对比赛结果、进球数、晋级概率给出相对可靠的定量预测,并在媒体、球队决策和商业场景中落地。预测模型的核心在于数据质量与建模逻辑,而应用前景取决于模型能否转化为可解释、可运营的产品服务。
2026世界杯扩军至48支球队,赛制和赛程结构变化,使得传统基于32支球队与小组赛三战的模型需要调整。建模时需要重新估计不同洲际球队的实力分布、疲劳影响和小组出线策略,这让预测难度上升,也为新一代模型提供了验证舞台。
常见的世界杯预测模型一般由三层组成:基础数据层、统计/机器学习模型层、情景模拟层。基础数据层负责整理球队与球员的长期表现,模型层将这些指标映射到胜平负概率和期望进球数,情景模拟层则在赛程框架下多次随机模拟全程赛事,输出夺冠、出线、淘汰概率分布。
关键数据指标与建模方法选择
2026世界杯预测模型要想具有稳定的解释力,需要围绕几个关键指标体系构建数据特征。大致可分为球队能力指标、球员能力与健康状况、赛制与外部环境三大类。
球队与球员指标体系
球队层面,常用的强度指标包括:基于比赛结果的Elo或Glicko评分、基于进攻防守的预期进球(xG/xGA)、过去两年对阵强队的表现,以及洲际赛事的稳定性(例如在美洲杯、欧洲杯、非洲杯中的平均分和进失球差)。
球员层面,核心关注点包括:主力球员出场时间、俱乐部层面xG参与度、防守端拦截与压迫数据、伤病历史以及赛季末疲劳程度。对中小球队来说,几名关键球员的状态对整体实力影响远大于大牌云集的强队。
外部环境方面,需要量化主办国和城市的海拔、气温、旅行距离、休息天数和时区差异,并将其引入预测模型中,作为疲劳与主场优势的修正因子。
主流建模方法及差异
建模方法大致可以分为三类:
- 统计回归模型:以泊松回归或负二项回归建模每队进球数,将球队进攻、防守能力和环境变量作为自变量。优点是结构清晰、可解释性强,缺点是难以捕捉复杂非线性关系。
- 机器学习模型:如梯度提升树、随机森林、XGBoost或LightGBM,将比赛作为样本,胜平负或比分区间作为输出。适合处理高维特征与交互效应,但若不加约束,可解释性下降,容易过拟合。
- 贝叶斯与层级模型:通过层级结构把国家队、球员、洲际差异统一进一个框架,能够自然处理样本不平衡与不确定性,用后验分布给出概率区间,对于世界杯这种小样本、大不确定性的赛事尤为适合。
在2026世界杯预测中,一个趋势是:组合模型比单一模型更可靠。例如先通过贝叶斯层级模型估计基础攻防强度,再用机器学习模型对特殊因素(战术风格、教练更换、极端天气)进行修正,最终通过校准保证输出概率符合实际频率。
预测逻辑与常见误判来源
针对“预测模型及应用前景”的搜索意图,判断逻辑与误判来源是核心关注点之一。高质量的2026世界杯预测需要明确:哪些因素应该被纳入模型,哪些只能作为定性参考。
从单场胜平负到整体晋级路径
单场比赛预测通常基于双方综合实力差、近期状态和场地因素给出胜平负概率,并通过双泊松或改进模型得到比分分布。在世界杯场景中,这样的输出还需要转换为晋级概率:
- 针对小组赛,引入三分制积分规则、净胜球和相互战绩排序规则,对每个小组进行上万次蒙特卡洛模拟,得到每队出线概率。
- 针对淘汰赛,在90分钟概率基础上加上加时和点球阶段。点球胜率可由历史点球数据、门将扑救率与主罚球员成功率综合估计。
- 针对整届赛事,通过全路径模拟生成夺冠概率分布和“最可能路径”,例如某队在不同对阵树结构下遇到强敌的频率。
这种自下而上的逻辑使得2026世界杯预测模型不仅能回答“谁更强”,也能回答“在具体赛程安排下,谁更占优势”。
常见误判与模型失效场景
世界杯预测中的典型误判有几个来源:
- 过度依赖历史名气:把传统豪门的历史战绩当作长期实力,忽略教练更换、阵容老化和战术革新的影响,导致对新贵球队的低估。
- 样本外战术变化:国家队在大赛中采取与预选赛、友谊赛完全不同的策略(极端防守、节能打法),让基于历史xG的数据失效,这需要在模型中纳入教练风格与大赛保守偏好。
- 小组赛激励错配:当某队提前出线或提前出局时,其真实动机会改变,但模型仍按照“必须全力争胜”的假设计算,这会显著影响末轮比赛预测。
- 伤病与状态更新不及时:2026世界杯赛程密集且跨国旅行频繁,若模型更新频率不足,无法及时反映核心球员受伤、轮换策略,就会出现明显偏差。
针对这些问题,实践中会结合实时信息流构建“动态预测模型”,在开赛前给出基础预测,在每轮比赛结束后重新校准球队强度与阵容可用性。
2026世界杯预测模型的应用场景与前景
预测模型的价值不在于“押中黑马”,而在于让不同参与者在不确定环境下做出更有依据的决策。2026世界杯扩军和北美多国举办的特性,为模型应用带来了新的场景和需求。
媒体、球迷与内容平台的可视化预测
媒体机构可以基于预测模型生成动态化的晋级树、夺冠概率排行榜、球队实力雷达图,为解说和专题报道提供数据支撑。球迷内容平台可以设计可交互工具,让用户自定义部分参数(如认为某队当前状态加成、主场权重),实时看到预测改变。
解释性将成为2026世界杯预测内容的竞争点:不只是给一个数字,而是说明“因为该队边路进攻效率是平均水平的1.3倍,而对手防守弱点正好在边路,所以进攻端被看好”等逻辑。
球队、教练组与对手分析
对于国家队教练组,预测模型可用于:
- 评估不同战术方案下的比赛结果分布,例如高压逼抢与稳守反击分别导致的失球风险。
- 在小组赛中根据出线概率与对阵组合,决定是否接受平局、是否需要追求更多净胜球。
- 结合球员疲劳和伤病风险,模拟不同轮换策略对后续比赛胜率的影响。
这些应用要求模型具备可操作接口,例如能在输入不同首发阵容和战术参数后快速输出新的胜率估计,而不仅仅是静态预测。
商业运营与合规场景
在合规环境下,预测模型可以为广告投放、赞助资源配置和赛事日程安排提供参考。例如,预测某场比赛成为“高关注度焦点战”的概率、某队晋级深度对品牌曝光回报的影响,从而帮助赞助商选择合作对象和投放节奏。
对于依法经营的数据服务公司,2026世界杯预测模型还可以包装成API或可视化产品,向媒体、俱乐部和分析师提供订阅服务,这部分是较具前景的商业化方向。
需要注意的是,任何涉及投注或金钱利益的应用,都必须严格遵守所在国家和地区的法律法规,对模型能力进行清晰披露,避免使用夸大或“稳赚不赔”式的宣传。
模型建设与使用中的实践建议
面向准备参与2026世界杯数据分析的机构和个人,有几条实践建议值得强调。
- 重视数据清洗与特征工程:对友谊赛、预选赛和洲际大赛进行分类型处理,不同级别比赛权重不同,避免把低对抗强度的数据等同对待。
- 引入不确定性表达:不要只给出单一概率点估计,为关键球队提供置信区间或分位数预测,帮助使用者理解“这只是众多可能世界中的平均结果”。
- 强化可解释性输出:在模型接口中设计“贡献度分解”,说明各项特征对预测结果的贡献比例,减少“黑箱”带来的不信任。
- 持续在线更新:2026世界杯期间采用滚动更新策略,在每轮比赛后重新校准球队参数,同时记录模型表现,用于赛后评估与改进。
- 区分专业与大众使用场景:面向普通球迷的界面需更简洁、强调图形化和故事化解读;面向专业分析师则应提供原始数据、可下载报表和模型配置说明。
综合来看,2026世界杯预测模型不再只是赛前出一张“夺冠概率图”这么简单,而是一个贯穿赛前准备、赛中动态调整和赛后复盘的综合分析体系,其应用前景将与数据产品化能力和场景理解能力紧密绑定。